

この記事は3年以上前に書かれた記事で内容が古い可能性があります
vdbenchのログをmatplotlibで分析した話
2017-01-30
vdbenchで出力したログを今までExcelで解析していたが、何十万行となるとExcelさんでは追いつかないので、重い腰を上げてmatplotlibに任せてみたら、思いの外捗った。
24万行近くあったが3秒くらいでグラフプロット完了。
以下のリンクを参考にしました。
http://myenigma.hatenablog.com/entry/2015/10/09/223629
とりあえず色々インポート
% pip install bumpy % pip install scipy % pip install matplotlib % pip install pandas % pip install seaborn
フォルダ構造
% tree . ├── seaborn_test.py └── summary_results.html 0 directories, 2 files
vdbenchのログ
※フィクションのため、実際のログとだいぶ違うかも
% cat summary_results.html <pre> Copyright (c) hogehoge Vdbench summary report, hogehoge 20:16:39.211 1 37451.00 819.53 22945 19.68 1.962 2.089 1.931 38.471 1.528 74.0 1 1 20:16:40.073 2 48067.00 1051.72 22943 20.15 2.167 2.260 2.143 202.375 3.789 105.3 1 1 20:16:41.070 3 50779.00 1110.13 22923 20.13 2.136 2.235 2.111 224.337 3.818 107.0 1 1 20:16:42.068 4 48873.00 1068.42 22923 19.96 2.170 2.323 2.132 262.347 7.321 106.1 1 1 20:16:43.065 5 49300.00 1078.91 22947 20.07 2.167 2.218 2.154 222.376 3.383 107.9 1 1 20:16:44.080 6 51324.00 1122.13 22925 20.12 2.175 2.262 2.153 402.594 4.084 110.6 1 1 20:16:45.060 7 51847.00 1133.87 22931 20.06 2.082 2.092 2.080 214.988 4.439 107.9 1 1
実行ファイルの中身
% cat seaborn_test.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sys
import linecache
import re
# グラフの種類
sns.set_style("whitegrid")
args = sys.argv
#見出し行
header_line = 3
filepath = args[1]
c = int(args[2]) + header_line
e = int(args[3]) + 1
data = open(filepath, "rU")
i = 1
while i <= header_line:
data_head = next(data) #見出し行を無視
i += 1
data_title = ["time", "interval", "iops", "MB/s", "bytes i/o", "read pct", "resp time", "read resp", "write resp", "resp", "max", "resp stddev", "queue depth", "cpu%", "sys+u", "cpu%", "sys"]
#何行目の項目を分析するか
#x_row = 1
y_row = 2
#y2_row = 5
x = []
y = []
#y2 = []
print("start line:%i" % (c - header_line))
while c <= e:
row = linecache.getline(filepath, c)
row = row.replace('"', '')
row = row.replace('/', '')
row = row.replace(':', '')
row = re.split(" +", row)
x.append(c)
y.append(row[y_row])
#y2.append(row[y2_row])
c += 1
print("end line:%i" % (c - header_line + 1))
total_len = len(open(filepath).readlines())
print("total line:%i" % (total_len - header_line))
plt.xlabel("log_line")
plt.ylabel(data_title[y_row])
plt.plot(x,y)
#plt.plot(x,y2)
plt.show()
いざ実行
% python seaborn_test.py summary_results.html 1 7 # python <実行ファイル> <分析対象> <始まり行> <終わり行> start line:1 end line:7 total line:7
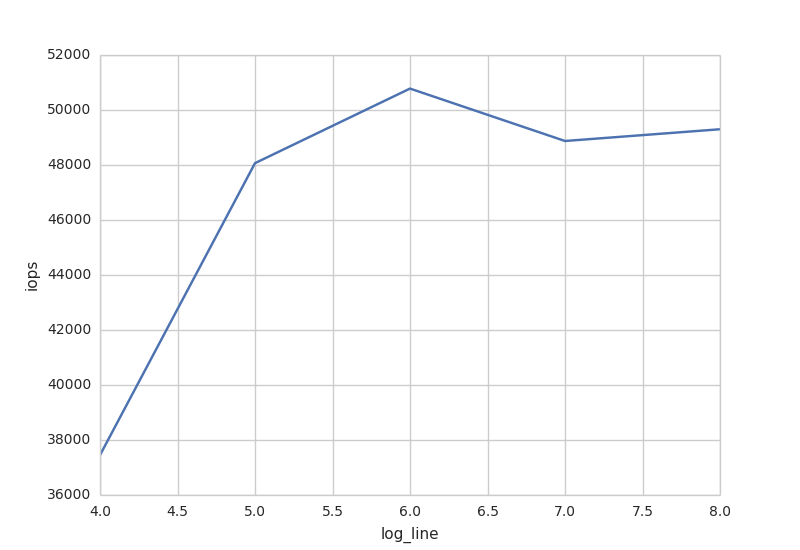
行指定をしたかったので、for row in data:ではなくwhileを使っています。
本当はx軸を日付にしたかったが日付をまたぐと順番が前後してしまうとか、
「/」とか「:」が入っているとエラーとなったり、日付の扱いが悩ましい。。


